Malaac Project ( Arabic Corpus )
Malaac System
Data Set #1 : Arabic_paraphrasing_benchmark
This dataset consists of 1010 Arabic sentence pairs where experts collected the first part in the sentence pairs from different Arabic books and some of these sentences are generated using words from AWSS dataset (Almarsoomi et al. 2013); the second part is transformed from the first part using six transformation rules for Arabic language. The six transformation rules are : permutation, replacement, deletion, addition, expansion and reduction.
Data Set #2: I3rab Dependency Treebank
Treebanks are valuable linguistic resources that include the syntactic structure of a language sentence in addition to POS-tags and morphological features. They are mainly utilized in modeling statistical parsers. Although the statistical natural language parser has recently become more accurate for languages such as English, those for the Arabic language still have low accuracy.
I3rab is a new Arabic dependency treebank based on the traditional Arabic grammatical theory and the characteristics of the Arabic language, to investigate their effects on the accuracy of statistical parsers. For example, in the sentence (محمد يقرأ الكتاب في المكتبة , Mohammed reads the book in the library), the verb (يقرأ , reads) is linked with the topic (محمد , Mohammed) by PRED dependency relation. Note that the verb (يقرأ , reads) is the main word of entire sentence (يقرأ الكتاب في المكتبة , reads the book in the library) and the dependency structure of entire sentence is governed by the verb (يقرأ , reads) and not by the noun (محمد , Mohammed) that is the main word in the whole sentence. The dependency structure of is illustrated in Figure 1.
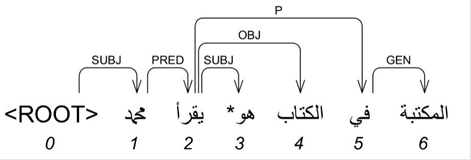
Figure 1: The dependency structure of the sentence (محمد يقرأ الكتاب في المكتبة , Mohammed reads the book in the library)
The current I3rab treebank consists of 601 sentences. These sentences are sampled from the PADT [1] [2] [3] on the basis of sentence length. The PADT was mainly collected from six news agencies. Figure 2 shows the distribution of the sentence lengths for I3rab treebank. While, Table 1 shows descriptive statistics for the I3rab treebank.
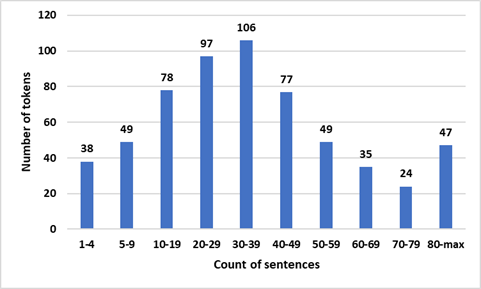
Figure 2: The distribution of sentence length for I3rab treebank
Table 1: Descriptive statistics for the I3rab treebank
I3rab treebank |
|
Number of sentences |
601 |
Total number of tokens over all sentences |
21480 |
Minimum number of tokens per sentence |
1 |
Maximum number of tokens per sentence |
102 |
Average number of tokens over all sentences |
36 |
Nominal sentences |
375 |
Verbal sentences |
225 |
- Linguistic structures of Arabic sentences from I3rab perspective
I3rab treebank based on I`rab theory. I`rab theory categorizes the Arabic sentence into nominal or verbal based on the class of the first word in the sentence. If the sentence starts with a noun, then the sentence is a nominal sentence. On the other hand, if the sentence starts with a verb, the sentence is a verbal sentence. From this perspective, I3rab treebank has 375 nominal sentences and 225 verbal sentences. Figure 3 shows the distribution for the type of sentence in I3rab treebank.
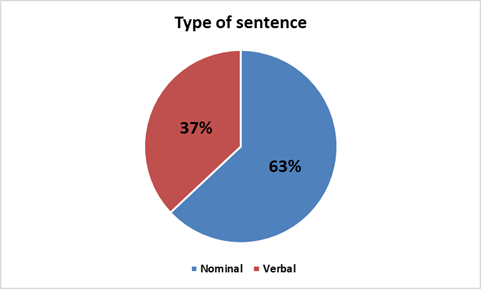
Figure 3: the distribution for the type of sentence in I3rab treebank